




Unicode
What is Unicode?
Universal character encoding standard for written characters and text. Covers all the characters for all the writing systems of the world, modern and ancient. It also includes technical symbols, punctuations, and many other characters used in writing text. Widely used and supported.

Basic Concepts
Codespace: the range of integers used to code the characters. Code point: an element of the codespace, i.e., an integer encoding a character.

Code Points
When referring to code points, the usual practice is to refer to them by their numeric value expressed in hexadecimal using four to six digits, with a U+ prefix.
- Leading zeros are omitted, unless the code point would have fewer than four hexadecimal digits.
- Examples: U+0020, U+265F, U+130E0

Properties
Unicode associates a rich set of semantics with characters (code points), these semantics are defined by character properties.
- Unicode identifies more than 100 different character properties, such as:
- Name
- General category (letter, number, symbol, punctuation, ...)
- Case (uppercase, lowercase, titlecase)
- The Unicode Character Database (UCD) contains character properties: unicode.org/ucd

Character Names
Each character is identified by a unique name, such as:
- U+0041 – LATIN CAPITAL LETTER A (A) fileformat.info/info/unicode/char/0041/inde..
- U+2605 – BLACK STAR (★) fileformat.info/info/unicode/char/2605/inde..
- U+1F63A – SMILING CAT FACE WITH OPEN MOUTH (😺) fileformat.info/info/unicode/char/1f63a/ind..

Characters and Glyphs
- The character identified by a Unicode code point is an abstract entity, such as LATIN CAPITAL LETTER A or BENGALI DIGIT FIVE.
- A visual representation of a character is called a glyph.
- The Unicode standard does not define glyph images.
- The visual appearance of characters on a device (e.g., screen or printer) is fully left to the software or hardware responsible for rendering characters.

Codespace
The range of integers from $0{16}$ to $10FFFF{16}$. The total number of code points is 1,114,112 of which 144,697 are used currently. Character code charts: unicode.org/charts

Planes and Blocks
The codespace is divided into planes, each of which contains 65 536 ($2^{16}$) code points.
- The last four hexadecimal digits in each code point indicate a character’s position inside a plane. The remaining digits indicate the plane.
- For example, U+130F7 is found at location $30F7_{16}$ in Plane 1.
- The total number of planes is 17 ($0{16}$, ..., $10{16}$).
- Planes are divided into non-overlapping blocks.
- Blocks are named ranges, where the number of code points in a block is always a multiply of 16.
- Characters used in a single writing system may be found in several different blocks.
Basic Multilingual Plane (BMP)
The plane containing the first 65,536 code points (range U+0000–U+FFFF) (Plane 0). Contains the common-use characters for all the modern scripts of the world as well as many historical and rare characters. By far the majority of all Unicode characters for almost all textual data can be found in the BMP.
Character Encodings
Character encodings defined by the Unicode standard:
- UTF-8
- UTF-16
- UTF-32
All three encoding forms can be used to represent the full range of Unicode characters. The abbreviation UTF stands for Unicode transformation format.
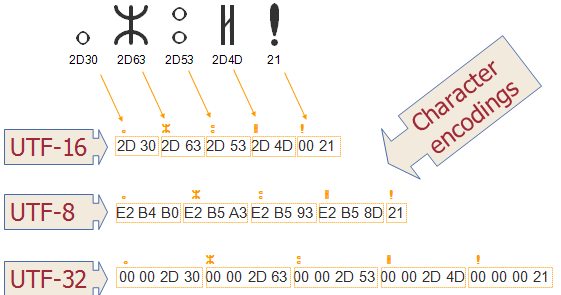
UTF-32
Each code point is represented by 4 bytes (fixed-width character encoding form). The simplest Unicode encoding form. The most efficient in terms of processing. The least efficient encoding in terms of the number of bytes used.
UTF-16
Each code point is represented by 2 or 4 bytes (variable-width character encoding form):
- Code points in the BMP are represented by using 2 bytes, for all other code points 4 bytes are used.
Optimizes the representation of characters in the BMP:
- For code points in the BMP can effectively be treated as if it were a fixed-width encoding form.
Maintains a balance between efficient access and economical use of storage.
UTF-8
Each code point is represented by using from 1 to 4 bytes (variable-width character encoding form):
- Code points in the range U+0000–U+007F are represented by a single byte (the 128 ASCII characters).
- Code points in the range U+0080–U+07FF are represented by using 2 bytes.
- All other code points in the BMP are represented by using 3 bytes.
- Code points outside of the BMP are represented by using 4 bytes.
The first byte of a byte sequence representing a code points determines the number of bytes in the byte sequence. The most compact encoding in terms of the number of bytes used. It is less efficient when used for East Asian writing systems, such as Chinese, Japanese, and Korean.
Unicode in CSS
Unicode characters can be specified with escape sequences of the form \hhhhhh, where hhhhhh is a sequence of one to six hexadecimal digits representing the code point of the Unicode character.
- If the number of hex digits is less than six and a character in the range [0-9a-fA-F] follows the hexadecimal number, then a whitespace character must end the escape sequence.
- A whitespace character that immediately follows an escape sequence will be ignored.
- Example:
- \A9, \0A9, ..., \0000A9
- \262F, \0262F, \00262F
See: w3.org/TR/css-syntax-3/#escaping
![]()
Unicode in JSON
In strings, Unicode characters in the BMP may also be expressed using escape sequences of the form \uhhhh, where hhhh is a sequence of four hexadecimal digits representing the code point.
- Examples: \u00A9, \u262F
See: rfc-editor.org/rfc/rfc8259#section-7
Unicode in XML, XHTML
In text, attribute values, and literal entity values Unicode characters may also be expressed using character references of the form:
>&#nnnn; where nnnn is a sequence of decimal digits representing the code point.
>&#xhhhh; where hhhh is a sequence of hexadecimal digits representing the code point.
See: w3.org/TR/xml/#dt-charref
Unicode in HTML
A number of Unicode characters may be expressed using named character references of the form &name;.